



NVIDIA“Kepler”架构完测
浓缩是精华 GTX 680架构基础特性解读
拜全新设计的显存控制器所赐,NVIDIA显卡在GTX 400/500时代主要靠扩展显存位宽来提升带宽的被动局面结束了。从表1中你能看到,GTX 680的等效显存频率默认就达到了6000MHz的高度。
、GF110芯片内核图。在芯片设计中,显存控制器、光栅和缓存等单元是相当占用晶体管资源和内核面积的部分。相比GF110,GK104在显存控制位宽,光栅单元数量和缓存大小上都有所减少。所以我们看到以往占据芯片中心大量面积的控制单元在GK104上的比例明显减小,计算单元/控制单元的比例明显增高。")
GK104(左)、GF110芯片内核图。在芯片设计中,显存控制器、光栅和缓存等单元是相当占用晶体管资源和内核面积的部分。相比GF110,GK104在显存控制位宽,光栅单元数量和缓存大小上都有所减少。所以我们看到以往占据芯片中心大量面积的控制单元在GK104上的比例明显减小,计算单元/控制单元的比例明显增高。
此外,你能发现GTX 680相对GTX 580在晶体管数量上的提升是非常有限的。GTX 680内含35.4亿个晶体管,相比GTX 580增幅仅18%,这在工艺升级的跨代产品对比中是很少见的。相对的,同样是40nm到28nm的升级,HD 7970就从HD 6970的26.4亿晶体管大幅提升到了43.1亿,增幅达到63%。GTX 680如此小的核心如何保证性能提升?关键问题在效率上。
,每个GPC内含2个SMX计算集群,共计8个SMX计算集群。")
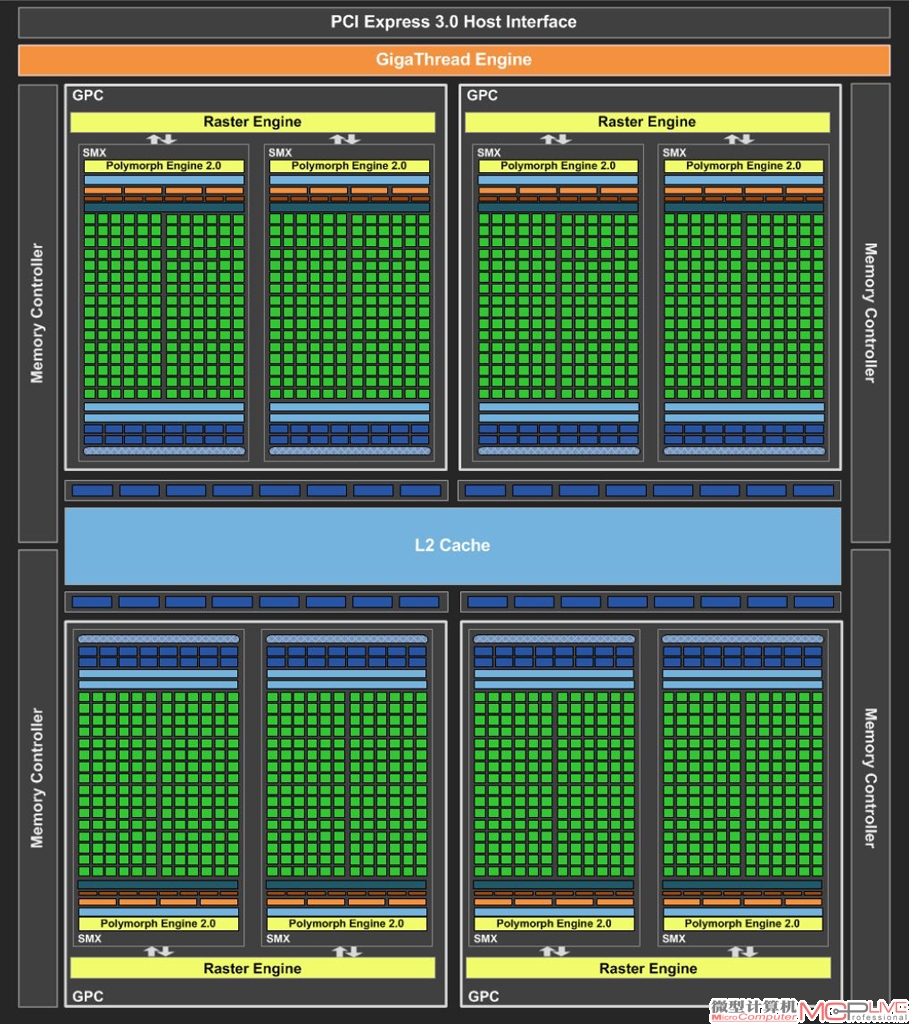
GK104整体架构图。它一共包含了四个图形处理簇(GPC),每个GPC内含2个SMX计算集群,共计8个SMX计算集群。

GK104 GPC架构图。每一个GPC都是一个比较完善的GPU次级单位,包含了图形渲染所需的几乎所有组件。每个GPC拥有一个共享的光栅引擎和两个相对独立的SMX计算集群。
,32个64bit存取单元(LD/ST),32个特殊函数单元(SFU),16个纹理单元(Tex)和缓存等组件。")
GK104 SMX单元架构图。它包含了Polymor ph Eng i ne 2.0引擎,192个CUDA计算单元,4个指令调度器(Warp Scheduler,包含两个指令发射器Dispatch Unit),32个64bit存取单元(LD/ST),32个特殊函数单元(SFU),16个纹理单元(Tex)和缓存等组件。
高度优化的计算/控制单元比例
从GK104整体架构图中我们能看到颇为熟悉的GPU——GPC——SMX——CUDA组成结构。很明显,基于“Kepler”架构的GK104传承了不少“Fermi”架构的设计思路,至少组织结构上没有太大变化,宏观上都采用了4个GP C的并行设计。不过仔细观察后会发现,虽然GK104和GF110在GPC单元数量上一致,但GK104的每个GPC模块仅包含2个SMX集群,而GF110的每个GPC模块则包含了4个SM集群。因此,GK104在SMX这一层上的规格相对前辈减半。要知道SMX这一层级的单元承载着诸如几何输出单元等重要计算模块的Polymorph Engine引擎,跟曲面细分等计算能力直接挂钩。简单点说SMX数量的减半也就意味着曲面细分计算单元的数量少了一半。那是不是在“Fermi”上强势的曲面细分应用优势将丢失呢?其实不然,NVIDIA在减少Polymorph Engine数量的同时,增强了每个Polymorph Engine引擎的效率。在一个时钟周期内,实现了比原有单元翻倍的吞吐性能。NVIDIA称它为Polymorph Engine 2.0引擎。因此,拥有8个Polymorph Engine 2.0引擎的GK104和拥有16个Polymorph Engine引擎的GF110,理论上每时钟周期几何处理能力是大致相当的。但使用了28nm新工艺的GTX 680在频率上更有优势,所以整体几何处理效能,特别是高负载状态下的性能GTX 680会比GTX 580更强劲。
除了更新Polymorph Engine引擎,以提高GK104芯片上单位面积的计算性能。NVIDIA的工程师还优化了GK104上的基础计算架构,以期达到在尽可能小的芯片内塞进更多计算核心的目的。如果你稍微留意过GF110的SM构成,你会发现“Fermi”的每个SM的内只有32个CUDA核心,也就是说SM内的一套逻辑控制单元只管理32个核心的工作调度。而GK104上,这个比例被放大到了192个。降低逻辑控制单元和指令发射器的比例,用较少的逻辑单元去控制更多的CUDA核心。从这个层面上来看,NVIDIA似乎借鉴了AMD经典的SIMD架构设计思路。有趣的是我们之前分析GCN设计构思时,发现AMD才大刀阔斧的改进了SIMD,向“Fermi”的MIMD架构靠拢。不管怎么说,拜这种思路所赐,GK104的流处理器数量(CUDA数量)达到惊人的1536个,在晶体管数量增加不到18%的情况下,将流处理器数量增加到了GF110的3倍。

硬件指令调度与软件调度的对比。你能看到整体的调度架构没有明显变化,但硬件执行过程被简化,硬件单元减少。
此时相信有读者会担心“降低控制单元的比例那是不是意味着NVIDIA从G80开始赖以成名的高效率将一去不复返?”理论上,肯定会导致效率下降,但真实情况是效率下降的问题并不严重。而这多亏了指令调度的“软”着陆。事实上,NVIDIA工程师发现线程的调度有一定的规律性,编译器所发出的条件指令可以被预测。在“Fermi”及以前,这部分工作是由GPU内专门的硬件单元来完成的。而在GK104上,这部分工作将根据预测性,交由简单的软件程序来处理。这样就能节约不少晶体管,简化CUDA单元,简化控制和调度单元的硬件设计。不过我们担心由此开始,N家的显卡也将出现比较明显的软件优化依赖,驱动或游戏的优化不到位将会明显影响“Kepler”架构的发挥。

每时钟周期“Fermi”、“Kepler”加法操作对比。你可以看到在同样的吞吐率下,“Kepler”的逻辑单元是“Fermi”的1.8倍,但是逻辑单元的耗电还低10%。时钟电路的面积一样,“Kepler”的耗电量只有“Fermi”的一半。
为了能耗比,频率不再分家
细心的读者可能已经从表1中看出GTX 680的规格中不再单独列出Shader频率,这是怎么回事?按照NVIDIA的说法,从G80时代开始采用的异步Shader频率设计是为了能在尽量少的芯片面积下实现更高的吞吐量。但这是以牺牲功耗为代价的,这种设计需要2倍于同步频率的流水线硬件,和双倍的重定时功耗。每个硬件单元的耗电高会达到4倍于同步频率的水平。现在,“Kepler”的设计改变了以往架构流处理数量明显不足的劣势,没有必要再沿用这种高功耗的设计。毕竟“Kepler”的目标不仅是提高性能还更注重能耗比。
解除绑定,让纹理质量向极致靠拢
在图形计算过程中,物体表面颜色细节需要纹理单元(Textuie)和Shader配合作业。在“Kepler”之前,GPU内每个Shader在一个周期内能访问的纹理单元数量是非常有限的。根据DirectX 11图形API的要求和映射表大小的限制,这个数量被限制在1∶128。而“Kepler”架构则消除了渲染场景时Shader可用独立纹理数量的限制。它允许着色器直接从内存中引用纹理,不再需要传统的映射表。依照NVIDIA的说法,着色器与纹理数的比例达到1∶100万也未尝不可。届时我们就能在游戏中看到更多如照片或电影般的精细贴图场景。只是目前这个特性只能在OpenGL中提供,未来将可能通过NVAPI在DirectX中实现,或者等待新版本的DirectX加入对该特性的支持。

解除绑定的免装箱机制不仅能让纹理更加精细,还能进一步降低CPU占用率。上图是以不同方式载入三张纹理到显卡的过程,左图为传统的装箱表式贴图配置,需要CPU执行三次配置装箱表动作,而右面“Kepler”体系的免装箱表贴图则完全消除了这三个动作。
好了,有关“Kepler”技术的介绍到此告一段落。有关GTX 680更多的功能特性就留在实际体验环节来为大家解读,先让我们一起来看看在架构上大幅改进后的GTX 680能我们带来怎样的实际游戏性能。


{kind=link}
{kind=link}