



从分析到构建 典型容灾案例解析
此容灾架构的核心技术采用了IBM Power570/595+DS8000+Metro/Global Mirror+Power HA XD集群来实现的。IBM Metro/Global Mirror技术是一种同步(Metro Mirror)+异步(Global Mirror)的层叠技术,它可以作到同城主中心A失效时,同城的灾备中心B的RPO基本为0,异地的灾备中心C处的切换响应时间也可控制在几分钟之内。生产中心的其中1台DS8000存储可以同异地远端的DS8000通过Global Mirror模式进行数据镜像,实现异地的数据备份及保护。通过对A、B和C中心之间的专线带宽进行估算(采用常用的OLTP+连续数据流估算组合),在数据中心A站点内部进行了一定调整。
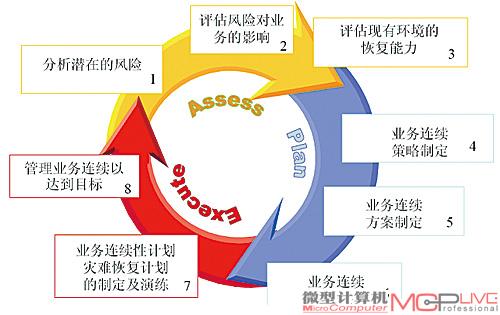
制定满足业务连续性的灾难方案出台之前应该做的事
在同城利用HACMP+PPRC(也叫Metro Mirror)的组合进行存储的本地数据复制,磁盘阵列本身为RAID 5或10的冗余方式,系统部件和网络均作了冗余性处理,应用方面也运行负载技术进行了高可用性处理。本地另采用虚拟磁带库作为离线数据备份手段,采购了专用的数据库复制、本地复制及管理软件。当数据中心A的主应用(或主磁盘)失效时,会瞬间切换到备应用(通过负载均衡检测技术)和备磁盘体系上,如果数据中心A出现故障,IBM的HACMP-XD(HACMP的WAN版本)技术会自动进行应用接管,启用灾备中心体系。基本流程如下:
1.HACMP-XD侦察到failover;
2.HACMP-XD在灾备中心启动PPRC secondary卷;
3.HACMP-XD在灾备中心重新启动系统和应用。
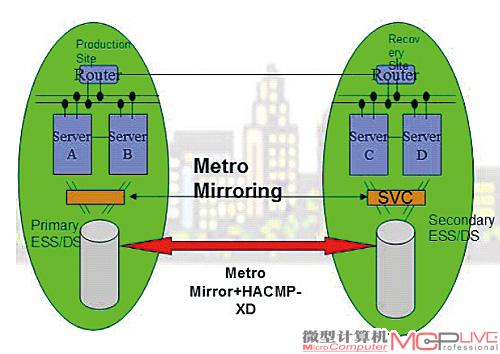
数据中心A站点容灾部分结构
容灾方案的制定和实施是一个非常复杂的过程,上述案例仅是概括性介绍,而且主要以数据存储容灾和应用自动接管为主进行介绍。至于数据库容灾、数据一致性检查、虚拟化存储机理、网络对容灾技术的支持(包括设备和相关专用协议、技术等),在这里暂不作介绍。
如果你对容灾解决方案有自己的看法和需求,欢迎发送邮件至chenzl@cniti.cn与我们讨论。
想要了解更多有关企业数据容灾的报道,请浏览以下的文章:
用户评论

