



DirectX 12下A卡、N卡多卡并联
多GPU能带来高分辨率下更出色的性能表现,展现别人难以看到的丰富游戏场景和精致细节。所以多卡互联向来都是发烧玩家的首选显卡组建方案。NVIDIA有自家的SLI技术,AMD也推出了CrossFireX,原本井水不犯河水。但相信不少玩家都有过“A卡和N卡放一起能并联吗?”的疑问,或者“A卡和N卡能并联工作就好了”的期望。这种想法看起来天方夜谭,但却并不违背DIY探索精神的初衷,只可惜在此之前玩家们折腾不出什么像样的混合并联组合。直到Windows 10携DirectX 12来到我们身边,系统开始提供原生的多卡并联工作支持,这才让我们首次有了实现A、N混交的基础。
那么A、N是不是真的能在Windows 10下握手言和?
混合并联是否真的能兼得N卡和A卡各自的特性?
混合并联的性能提升幅度比起SLI和CrossFireX来是否足够让人满意?
混合并联都有些什么限制,是不是所有DirectX 12游戏都支持?
实际组建混合并联我们又该注意些什么呢?本文将为你一一揭晓。
DirectX 12(本文接下来简称DX12)对微软来说无疑是一次重要的API更新,它一改以往为高级开发语言优化的思路,开始追求更接近底层硬件的高效率思路(本刊此前已经对DX12的技术做过全面技术预览,感兴趣的玩家请翻阅本刊去年5月刊的《应用与技术》栏目)。对行业来说,这种开发思路的转变无疑是一次深远的变革。初期可能带来开发投入增加、开发时间延长等阵痛,但原生的多核心支持能力、高效的显卡并行处理方案等新特性将帮助开发商更好地掌握底层硬件,发挥出硬件应有的性能,为用户带来更加炫酷、丰富的游戏体验。所以无论是开发业界还是玩家,对DX12的到来都是非常期待的。其中受玩家关注的无疑是DX12宣称支持的A、N卡混合并联特性,这是玩家们此前梦寐以求很久的组建方案。几年前,有一些厂商曾展示过别具心裁的A、N混合方案,想法虽好,但实际表现却并不理想,A、N各自的特性丢失殆尽,且相比单卡的性能提升也不能让人满意。鉴于此,DX12所带来的混合并联在效率上的具体表现就非常引人注意了,这决定了该特性的实用性究竟如何。接下来,我们先从原理上解析多卡并联工作的基本原理,以及DX12是如何打破A、N间桎梏,实现多显卡混合并联的。看看微软的新方式和之前的各种并联方案有何不同。
以往A、N为何不能混合并联?
其实各厂商之间的显卡并非不能并联工作,而是厂商在主观意愿上并不希望这样的事情发生,也不主动支持这样干的厂商或玩家。当然,A、N混联客观上也有一定问题。因为在此之前,无论是NVIDIA的SLI还是AMD的CrossFireX,多卡并联在工作时大多基于交替帧渲染模式(AFR,本文后续会有详细介绍)。AFR模式意味着显卡要在连续帧中做接力赛,GPU1、GPU2会交替渲染帧1、3、5、7……和2、4、6、8……。这其中涉及到GPU间需要通信,需要分享渲染数据和缓存互访等问题。很显然,A或者N都不太愿意向对手透露太多自家显卡在核心通信和显存互访中的核心设计。没有这样的相互合作,双方不可能在基于AFR工作模式的多卡管理驱动开发中顺利加入对对手显卡的支持,又何谈混合加速?
DX12究竟如何实现混合并联?
要明白DX12是如何实现混合并联的,就得从微软为DX12设计的三种多显卡作模式说起。正是在开发之初就有了明确的多核心和多GPU支持思路,才让DX12看起来那么诱人。
相对传统的IMA
Implicit Multi-Adapter(忽略性多卡适配,简称IMA),是微软声称的简单易得的多GPU互联方式。它使用的还是类似DX11时代的渲染方式,特点是不需要改变现有游戏的系统设计,非常容易实现多GPU从DX11到DX12的过渡,可以让游戏开发商保留传统制作习惯,快速移植作品。但问题是这个工作模式决定了它也传承了DX11下遇到的多卡并联的各种传统问题,并联工作的GPU差异不能太大、灵活性不足,而且不能充分发挥多GPU的加速优势,终提速性能对原厂驱动的优化程度依赖依旧极大,在各游戏中提供的性能体验参差不齐。
Tips:混合并联的梦由来已久
早在2010年之前,在DX11还没有普及开的时候,A卡和N卡各有优势,例如A卡能够支持当时尚属前卫的DX11,并且支持UVD2,在API新特效和高清方面有更好的表现。而N卡可以提供独特的PhysX物理加速,可以支持3D显示等等。玩家们都知道两张A卡可以通过CrossFireX并联工作,两张N卡可以通过SLI并联。但只能在这两个方案中选其一,也就是要么获得A卡特性,要么获得N卡特性。鉴于A、N卡各具特色,想要将这些特色一并拥有的用户就开始期待“要是能让一张A卡和一张N并联起来工作,那真是能有的都有了。”或者心存拿一张A卡做主卡,让N卡来协助物理加速等“异想天开”的想法。

Lucid是混合并联的先行者,理念看起来不错,但实际产品的效果并不理想。


随后真有微星等厂商借助LucidHydra芯片推出了混联主板,只可惜它一直不被AMD和NVIDIA正式认可,缺乏优化、效果不佳,现在基本夭折。要想混联,或许只能看顶层的系统设计者—微软。
两种诱人的EMA
相比IMA,DX12提供了相对更高级的Explicit Multi-Adapter(精准多卡适配,简称EMA)模式。这个模式对开发者的要求高得多,顾名思义,它需要开发者在游戏和驱动开发之初就明确地为多GPU优化,提供“原生”的多GPU工作环境。包括GPU负载分配、显存分配、各GPU间核心通信等,要求游戏和驱动对API拥有深度理解和绝对控制权。很显然,这会明显增加开发者的难度,需要更多开发时间,消耗更多开发资源。而好处则是多卡组合的灵活性将得到足够保证,这是因为EMA模式的多GPU协作又进一步细分为了链接型和未链接型两种。
链接型EMA(link mode),这种模式下,多个GPU将会被统一为一个单位,被系统视为一个GPU。这种工作方式对并联工作的多个GPU的要求和SLI、CrossFireX类似,要求规格相近,好是同规格产品并联。因为PCI-E总线、指令处理器和显存池等都是分开的,所以实际运作时,虽能调用多个GPU核心资源,但仍然容易受到外围模块的木桶效应影响。而尽量统一规格能降低木桶效应。此模式相比SLI和CrossFireX的大不同,可能就是对显卡品牌几乎没有要求,让混合并联成为可能。而且基于EMA方式时,并联系统更依赖于系统和游戏的优化,对AMD、NVIDIA原厂驱动的依赖相对减少,至少并不需要彼此间过多的相互协作、沟通。

微软介绍的DX12下IMA的主要特性

玩家们非常熟悉的SLI技术就是典型的IMA实际应用类型,要求协作显卡性能不能相差太明显。
无链接EMA(unlink mode),这与之前的SLI和CrossFireX完全不同,它支持任何厂商的独显、集显的混合组合。多家厂商之间的产品也可以任意搭配,也就是可以无条件混合并联。重要的是每个加入并联工作的显卡依旧保留自己独立的显存、指令控制等资源,通过EMA层灵活交换任何需要用到的共享数据。这种工作方式可以理解为并联后的资源叠加,比如两张4GB显存的显卡在这种模式下并联后,这套系统的实际可使用显存等效就是8GB了。很显然无链接EMA是不少玩家们期待DX12的一大原因,但少有玩家知道其实无链接EMA原本是为独显+集显而准备的特殊技术。希望集显能分担渲染任务中,容易被预料到的有些后期处理和简单渲染,以便让独显更专注地将精力投入高复杂度的图形处理任务中。所以这套系统的灵活度虽高,但在面对独显+独显的高配组合式时,实际效率如何还有待考验。用微软的话来说,DX12提供的是一个丰富的底层支持,给了开发商若干可能性。至于终独显+集显,同一家厂商的多张独显,或者不同厂商的多张独显是否能在游戏中展现出优秀的加速效果,完全取决于开发商对API的掌握能力和对游戏的优化程度。也就是说这是软件的问题,跟选择什么硬件关系不大。
AFR和SFR
相比IMA,EMA,尤其是非链接型EMA的特性看起来如此迷人,却少有人知道背后功臣其实是染模式的转变。在以往,NVIDIA的SLI在实际的渲染流程中,多遵循AFR(alternate frame rendering,交替帧渲染)方式;AMD的CrossFireX系统使用类似的瓦片分离渲染模式(Supertile Mode)。这种方式的原理是让系统中的多个GPU,分别渲染连续的单独帧。以双GPU为例,GPU1渲染第一帧,GPU2渲染第二帧,然后GPU1接着渲染第三帧,GPU2渲染第四帧……依次循环往复。AFR方式是非常直接的多GPU使用方式,其渲染原理完全遵从传统的游戏渲染机制,对游戏来说多数情况下跟使用一个GPU没有什么区别,所以兼容性是好的。

微软介绍的EMA模式主要特性

微软介绍的未链接型EMA主要特性

EMA多GPU互联显存交叉适配管理机制图示
但AFR的缺陷也非常明显,交替帧意味着需要显卡花费额外的开销来处理帧之间的连续性,比如渲染跟踪、前后帧侦测等。另外,这样的方式也需要额外的工作分配机制和整合机制,保证多GPU能正确渲染属于自己的那些帧,以及按照正确的顺序输出帧,而不至于让画面混乱。再者,因为交替渲染会单独考验每个GPU的性能,要想让整体画面平顺流畅,就需要参与的GPU核心性能相当。如果让两张性能差异过大的卡来并联,会出现较快的卡早早渲染完一帧后,花更多时间来等待较慢的卡渲染好第二帧才能开始第三帧的渲染工作,这显然会影响整体效率。所以NVIDIA的做法是组建SLI的显卡必须是同型号。AMD的CrossFireX要求稍微放宽,但也要求多GPU是同样档次的核心,比如当前的旗舰和次旗舰R9 FruyX、R9 Fury可以组建交火。
在这个问题上,Lucid曾推出过名为LucidHYDRA的多卡互联芯片,改进过AFR的问题。Lucid从多芯片同卡互联的通信芯片开始,在A和N各自的双芯旗舰显卡中,起到过相当重要的作用,也是不少高端主板首选的GPU互连辅助芯片。其跨厂商互通的LucidHYDRA方案也确实有独道之处,主要是工作模式的创新,它既不简单地直线分割每一帧画面,也不会机械地将各帧画面分配给各个GPU,而是将整个画面渲染工作灵活分配。在渲染任务到达LucidHYDRA芯片后,它会按运算量划分为多个任务包,交给系统中不同能力的显卡完成。每个任务包可能是一个特定的光照效果,一种后期处理,一个特定模型的绘制等等。各GPU完成自己的运算任务后,会把结果(可能是一部分数据、也可能是一些像素)分别交还LucidHYDRA芯片,该芯片再把这些信息交给其中一颗GPU做后的整合,完成一帧渲染后输出。鉴于此独到创新,微星等厂商就推出过基于LucidHYDRA芯片的混联主板。但因为始终得不到AMD、NVIDIA的支持,而在兼容性上有些问题。再加上工作原理复杂,在实际执行中互联提升幅度并不明显,远逊于SLI和CrossFireX,没能实现玩家们既得A、N两家特性于一体,又能翻倍显卡性能的愿景,所以已经慢慢沉沦了。

AFR和SFR的工作原理微观理解,AFR依旧是单卡工作,但为两卡轮番上阵;SFR则是真正的两卡同时工作。
现在想起来,LucidHYDRA的思路其实不错,有些类似SFR。但实际产品却走入了一个恶性循环,因为这种分配方式对驱动的依赖性太高了,需要原厂驱动不断地优化对游戏的支持,甚至每出一款新游戏就需要一个特定版本的驱动。AMD和NVIDIA改善自己的驱动去优化CrossFireX和SLI都还来不及,哪里有富余时间来管LucidHYDRA?那么,倘若有一个比LucidHYDRA更优秀、高效的方式来管理多个GPU,完善渲染链前段的工作分配任务,那么多显卡并联系统的效率无疑会提高很多。而这就是DX12追寻的方向,也是SFR进入DX12与EMA搭档的关键。
完全有别于以往AFR渲染模式,SFR(Split Frame Rendering,分割帧渲染)工作方式是类似于LucidHYDRA的按需分配方式。它可以将一帧画面的渲染任务,分配给多张不同的显卡。这个不同不仅仅是指品牌、核心架构不同,甚至可以是性能档次差异巨大的型号,或者新旧不同的两代架构等等。其实这也并不是一个新技术,在以往的SLI技术展示中,NVIDIA就曾演示过多卡SFR渲染方式。只不过在当时的IMA模式下,要实现这种混合渲染对游戏的开发要求太高,没有类似DX12这样的API支持,单因一款游戏而去重做一个引擎,重构软件底层是非常痛苦的。所以这个先进的机制一直处于尘封状态,直到微软决心从底层开始对它提供支持。因为它能根据显卡性能,合理匹配显卡性能,让负载相对均衡。这考验的是渲染前期的信息处理能力,在DX12原生多核心CPU的支持下,加上游戏厂商的大幅度优化,是完全可以实现按能力分配负载的理想状态的。更重要的是,这种方式对任何一帧画面来说都是多显卡叠加工作的成果,而不像AFR,要求单张显卡渲染完整一帧。这意味着对系统来说,每一块显卡的资源是叠加的,包括PCI-E带宽资源、显存资源等等。以前两张显存4GB的显卡SLI等效可用的还是4GB,因为副卡的显存都用作帧缓冲区镜像,放置和主卡显存一样的数据。而SFR模式下可以简单理解为4GB+4GB等效获得8GB显存资源,对于高分辨率游戏玩家来说这绝对是极好的消息。
混合并联只能是Win 10+DX12独享
要想开启混合并联,除了必须将系统升级到Windows 10以外,玩家还需要找到基于DX12 API开发的游戏,才有“可能”尝试到该特性。至于游戏对混合并联的支持力度如何,还得看开发商在研究DX12底层特性上面花的功夫够不够深了。本次测试,我们原本希望找到足够多的DX12游戏,以尽可能丰富的范本为玩家展示DX12的混合并联特性,好是能将IMA、非链接EMA和链接型EMA,以及对应的AFR、SFR等工作模式全部包含,这样才具参考性。但是在我们截稿前,我们收罗了当时能测试的所有基于DX12开发的游戏,甚至是通过特殊方式能开启DX12模式的游戏,发现情况并不乐观。严格意义上来说,当前没有一款正式的基于DX12 API开发的游戏。现在的各种“测试版本”并不能为我们提供足够的样本,没有办法测试非链接型EMA、SFR等比较新颖的互联、渲染方式。具体情况如何,接下来测试中将为大家详细介绍。
当前DX12游戏和引擎介绍
以往API新老交替之际,微软都会和伙伴提前合作开发新游戏。在新API正式上市的时候,基于新API的显卡硬件和游戏软件也都基本上准备就绪了。不过本次DX12换代显得并不顺利,到截稿前我们能勉强体验到的DX12游戏只有3款。其实微软依旧提前和众多合作伙伴展开了合作,准备了许久,但这一次的API更新进度确实显得更加缓慢。首先是硬件上,微软虽然声称更老的诸如GeForce GTX 200系列和Radeon HD 5000等都能支持DX12,但我们知道DX12是有分级的,老显卡显然不可能提供对DX12的完整支持。而新显卡方面,即使是面对AMD的Fiji和NVIDIA的GM200等当前顶级的显示核心,微软也依旧三缄其口,没有承认它们对DX12的“完全”支持,只是说肯定是支持的。究其原因,本次从DX11到DX12的升级换代幅度,相比DX10到DX11的幅度大得多,革命性技术颇多。要想让原生多核心、硬件ACE得到支持和普及,让更接近底层、效率更高的开发方式获得广泛支持,都可能需要不少时间。
1、《奇点灰烬》
制作公司:Stardock
游戏引擎:Nitrous
游戏类型:即时战略RTS
发行时间:2016年第四季度,当前有Benchhmark测试工具放出可供测试参考。

《奇点灰烬》采用Oxide Games的Nitrous引擎打造,该引擎由微软加盟合作开发。和大多数当前使用的游戏引擎基本都基于老技术不断升级改造不同,Nitrous引擎是款从2013年才开始打造的的全新引擎。当前使用老引擎开发的游戏,同屏幕只能出现少量独特的、高精度的3D模型。这是因为目前的3D引擎是32位架构,主要依赖于CPU的“主线程”来与GPU互联。Nitrous引擎与之不同,它使用了原生64位架构进行开发,是多核游戏引擎,能更好地分发挥硬件性能。让该游戏任何时候都可以在同屏幕上更轻松地渲染超多数量的游戏单位。制作公司更是声称该游戏的视野超出了玩家玩过的任何一款游戏,它不只描绘一场战争,而是还原整个战场。更重要的是,作为极少数提前公布了Benchmark的游戏,更是受到不少媒体和喜欢尝鲜的玩家的重点关注。它也因此成为相当长时间内,大家初尝DX12特性的唯一选择。
2、《古墓丽影:崛起》
制作公司:Crystal Dynamics
游戏引擎:Crystal Engine
游戏类型:动作游戏ACT
发行时间:2016年1月26日

作为一款人气游戏续作,《古墓丽影:崛起》已经是该系列的第10部作品,并且已经于2015年11月10日在Xbox One平台上正式发布。得益于主机平台硬件和PC硬件的高度一致化,该作移置到PC平台的进度无疑会非常迅速,官方给出的预计发售时间是今年的1月26日,不过截稿前我们没法体验到该作品,后续会尽快补上有关该游戏的混联测试。
至于大家关注的硬件性能,游戏开发商表示:“我们对原来的Crystal Engine再次做了大量的改进,使得其支持DX12特性。”对显卡的性能要求上,得益于DX12更出色底层优化,估计并不会比前作提升太多,但A卡用户依旧更有优势。其一,是开发商一直在游戏开发中和AMD紧密合作;其次,则是A卡的硬件ACE也更加利于DX12高效运作。
3、《咖啡因》
制作公司:Incandescent Imaging
游戏引擎:虚幻4
游戏类型:冒险游戏AVG
发行时间:第一章节已于2015年10月5日于PC平台发布

说到著名的游戏引擎,虚幻系列绝对是玩家心目中的经典之一。而且新一代的虚幻4引擎,也是早宣布支持DX12的游戏引擎之一。只是因为各种各样的原因,基于虚幻4引擎的游戏迟迟未能和玩家们见面,目前只有一个未完成的《咖啡因》科幻恐怖游戏能让大家解解馋。之所以说“未完成”,主要是因为该作品只在去年的10月5日放出了第一章节的内容,而非全部游戏内容。该章节游戏体积不到2GB,玩家们也可以推测出当前游戏内容的匮乏和特效的不完善程度了。其实,这款游戏在2014年开发之初是使用虚幻3引擎进行制作的,之后随着虚幻4和DX12的逐渐成熟,制作组才转而采用更为先进的虚幻4引擎进行游戏开发。换引擎可能会耽搁不少时间,这很可能是该作暂时只能放出一章的重要原因。
4、《星球大战:前线》
制作公司:Electronic Arts Inc
游戏引擎:寒霜引擎
游戏类型:第一人称射击FPS
发行时间:已于2015年11月14日发行PC版

资深玩家对寒霜引擎也绝对不会陌生,作为EA旗下的引擎开发商,DICE对DX12一直都很支持。早在去年4月份时,DICE就曾明确表态,2016年的寒霜引擎游戏Windows 10,DX12都是低系统需求。在此之前已经诞生了大量基于寒霜引擎的优秀游戏作品,其相比同时代引擎显得非常出众的游戏画质是不少玩家热爱的重要特点。包括大名鼎鼎的《战地》系列战争游戏,都以画质著称。不过DICE早就公开发言,旗下已发布的《战地》系列都不会更新DX12补丁,想要体验DX12可能要等《战地5》了。但有玩家发现,已经发布的另一款DICE开发的游戏—《星球大战:前线》却能曲线救国地支持DX12,可以开启隐藏的DX12模式,只不过会带来游戏运行不稳定的后果,只适合迫不及待要想尝试寒霜引擎DX12效果的玩家。
5、《神鬼寓言:传奇》
制作公司:Lionhead Studios
游戏引擎:虚幻4
游戏类型:角色扮演RPG
发行时间:预计2016年第四季度

这是一款多次被业界巨头拿来做效果展示的DX12游戏,其DEMO被微软、NVIDIA等上游厂商宣传过多次,所以在玩家圈中也算小有名气。而且对玩家来说,该作在玩法上的创新,以及PC玩家可以和主机玩家联机等特性也确实让人跃跃欲试。就硬件要求来说,该作也是款使用了虚幻4引擎的游戏,所以要求肯定不会太低 。从已经公布的游戏DEMO效果看,该游戏对粒子、水面和光阴等元素的处理非常精细,这势必会消耗大量计算资源。不过开发商也宣称,DX12具有更高效率,同硬件平台下能获得比DX11更精美且更流畅的游戏运行效果。
混联性能实测
由于当前DX12游戏相对匮乏,我们的测试只能以《奇点灰烬》和《咖啡因》第一章为主,不太成熟的《星球大战:前线》为辅。这几款游戏当前所支持的模式并不丰富,渲染模式依旧是AFR,要求尽量选择同性能档次的产品进行并联。所以我们在测试时,无论A、N都选择了当前的顶级产品。A卡选择了公版的R9 Fury X,N卡则选择了非公版的GTX 980Ti,由于工作频率比公版高出了近20%,所以实际性能比公版GTX TITAN X还稍强。至于处理器,为了避免成为这套多GPU平台的瓶颈,我们选择了当前顶级的Intel X99平台,使用了8核心16线程的i7 5960X处理器和4GBx4的四通道内存系统。并将处理器超频到3.5GHz,内存运行在3000MHz的XMP频率上。除了用于对比的单卡数据,显卡系统皆采用双卡并联方式,SLI是两张GTX 980Ti,CrossFireX是两张R9 Fury X,混合模式则是R9 Fury X加GTX 980Ti。其中混合模式会分别让A、N充当主卡,获得两组测试数据。这里需要注意,一是正确安装A、N原厂驱动;二是注意主卡选择。所谓主卡,其实很简单,就是连接显示输出的卡,系统会自动识别并将渲染前端任务分配等工作交给该卡负责。

《奇点灰烬》EMA GTX 980Ti x2 vs. SLI GTX 980Ti x2性能测试成绩对比一览
{kind=link}

《奇点灰烬》EMA R9 Fury x2 vs. CrossFireX R9 Fury x2性能测试成绩对比一览

《咖啡因》EMA GTX 980Ti x2 vs. SLI GTX 980Ti x2性能测试成绩对比一览

《咖啡因》EMA R9 Fury x2 vs. CrossFireX R9 Fury x2性能测试成绩对比一览
A、N真能混合 并能逆袭原厂并联技术!
我想玩家们首先想知道的就是A、N是否真的能混合工作,答案是肯定的。而且在我们的本次体验中,这种混合方式甚至能展现出比SLI和CrossFireX更出色的并联工作性能。接下来我们将分别介绍各个组合的表现。
在我们测试的3款游戏中,《奇点灰烬》是值得研究的。作为DX12的编写者,没有人比微软更了解自己的API,而微软参与了该游戏引擎Nitrous的开发,这意味着该游戏和其所用的引擎将在一段时间内成为DX12开发者眼中的教科书,绝对是当前具代表性的DX12体验工具,对DX12特性的展现非常有发言权,对衡量未来DX12游戏对显卡的需求也具有极高参考性。此前AMD R9系列显卡在该Benchmark中大放异彩,也是因为AMD R9 Fury、R9 390X等显卡已经具备硬件ACE单元的缘故,故而能在支持ACE异步计算的应用中发挥出更优秀的性能。而我们本次测试的重点是EMA,这是实现不同厂商显卡混合并联的关键。它和传统的IMA方式的并联效率究竟孰优孰劣是大看点。值得注意的是,该Benchmark提供的EMA为“linked mode链接型”,这就意味着渲染模式依旧是AFR。所以我们还不能体验到一张高端卡和一张低端卡通过SFR渲染方式并联时的性能提升幅度。但就混联对比SLI、CrossFireX来说,却再合适不过。同为AFR渲染方式,可以清楚展现EMA相对IMA的优劣。
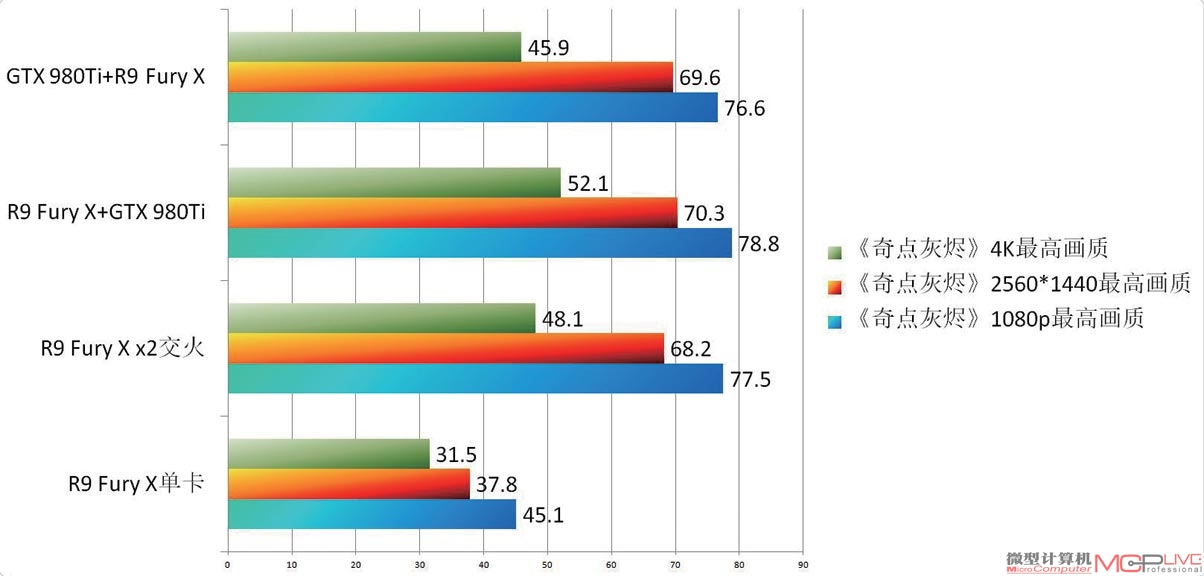
从测试成绩我们可以看出,此Benchmark的成熟度已经很高了,对传统的IMA多卡并联支持力度并不比当前优化较好的DX11游戏逊色。无论是SLI还是CrossFireX都表现良好。相比单卡,CrossFireX双卡的性能平均提升了68%左右,SLI的双卡相比单卡的平均提升也超过了40%。接下来是精彩的EMA混合并联模式,R9 Fury X作主卡搭配GTX 980Ti时,比CrossFireX和SLI组合的提升幅度都高。在1080p画质下,R9 Fury X的交火组合比R9 Fury X单卡提升了72%;GTX 980Ti的SLI系统比单卡提高了54%。而R9 Fury X+GTX 980Ti的混合组合比单张R9 Fury提升了75%,比单张GTX 980Ti提升了70%,大幅度超过了原厂提供的并联组合方式。接下来提高分辨率到2560×1440, R9 Fury X+GTX 980Ti的组合比R9 Fury X单卡提升了80%还多,比GTX 980Ti高出78%,明显强过CrossFireX 80%和SLI 52%的提升幅度,进一步将分辨率提高到4K情况也依旧雷同。EMA的效果显然已经超过了传统的IMA,混合并联有足够实力超越原厂的并联方案。

《奇点灰烬》GTX 980Ti+R9 Fury混合 vs. CrossFireX R9 Fury x2性能测试成绩对比一览

《奇点灰烬》GTX 980Ti+R9 Fury混合 vs. SLI GTX 980Ti x2性能测试成绩对比一览

《咖啡因》GTX 980Ti+R9 Fury混合 vs. CrossFireX R9 Fury x2性能测试成绩对比一览

《咖啡因》GTX 980Ti+R9 Fury混合 vs. SLI GTX 980Ti x2性能测试成绩对比一览
另外,在这款测试程序中,我们发现混合并联的性能跟谁作主卡有明显关联。同样是R9 Fury X和GTX 980Ti的组合,R9 Fury X作主卡时,混合并联平台的性能比GTX 980Ti作主卡高一些,各种分辨率下皆如此。因为主卡要负责前期任务分配和后期整合输出等任务,而A卡具备的硬件ACE单元更加有助于前期任务的高效分配,高带宽的HBM显存系统显然也有利于增强后端数据吞吐能力,提高整合输出效率。我们猜测可能正是依靠这些优势,A卡作主卡时的系统瓶颈更少,更能充分发挥多GPU高规格计算单元的性能,才导致了这种现象的产生。
接下来是《咖啡因》。和《奇点灰烬》有个教科书似的引擎不同,虚幻4是个由DX11改进而来的引擎,再加上游戏尚未开发完成,所以这个“第一章”的测试结果对后续DX12游戏表现的参考性相比《奇点灰烬》弱很多。就当前测试来看,该游戏对显卡并不友好,在我们的测试中同分辨率下单卡的平均帧率比《奇点灰烬》中的成绩还低,但画质和同屏幕场景复杂度却远不及《奇点灰烬》。而且它对原厂的交火和SLI系统的支持也不算好,提升幅度普遍不超过30%,和当前主流DX11游戏有平均超过50%的提升来说,该游戏的优化可以用不太到位来形容。更糟糕的是,该作并没有发挥出EMA特性的优势,混合并联的效果甚至比基于IMA模式的原厂并联还差,整体性能提升仅20%左右。不过在主卡互换的测试中,依旧是A卡作主卡时性能更高一些。
至于《星球大战:前线》,我们按照国外玩家的经验在游戏路径脚本后面添加-Render.DX12Enable 1。修改后我们并不确定真的打开了所谓的隐藏DX12模式,但是游戏开始变得不稳定倒是实情。无论A卡还是N卡,单张工作的时候尚能通过测试,但双卡工作模式时,只有A卡CrossFireX可以获得测试成绩,N卡SLI不能顺利通过测试就会崩溃,而混合并联则几乎没有提升效果。所以终我们放弃了将该项测试的成绩纳入对比。
可以不再关心SLI或CrossFireX授权?
其实在测试完混合并联后,我们已经对EMA模式的实力有所了解。但是我们依旧觉得缺少同环境对比,所以基于《奇点灰烬》我们进行了另外一项更具对比性的测试—两张R9 Fury X CrossFireX vs 两张R9 Fury X EMA;和两张GTX 980Ti SLI vs 两张GTX 980Ti EMA的直观对比。EMA测试中我们在AMD和NVIDIA的驱动中分别禁用了CrossFireX和SLI,但在Benchmark的选项中勾选上AFR交替帧渲染选项。测试结果显示在禁用交火和SLI后,系统依旧能依靠链接型EMA机制让多张显卡并联工作。而且同比相同分辨率下的CrossFireX和SLI,还能有效率上的优势。其中EMA双A卡相比CrossFireX系统的提升不算明显,大约有3%,但EMA双N卡相比SLI的提升就明显不少,超过了8%。毫无疑问,这再次证明了DX12革命性的EMA设计到底有多么优秀。结合上此前的混合并联测试,足以说明EMA相对IMA的优势。而且别忘了,这样的并联来自于系统特性,理论上所有基于DX12的游戏都应该支持。未来玩家们甚至可能淡忘原厂的并联技术,主板厂商或许可以省下SLI和CrossFireX的授权费了。
混合并联另一大优势—主卡特性可以保留
相对性能提升,我相信还有不少玩家更加关注的是混合并联时,兼得A、N两家特性的愿景能否在DX12上实现。这曾是Lucid和不少玩家的追求,但在此之前还没有成功过。这次测试EMA模式,虽不能说成功兼容了A、N两家特性,但至少成功了一半,主卡的特性完全能够保留。用N卡作主卡时,连接G-sync显示器依旧可以正常开启G-sync功能。A卡除了Freesync,还能开启Eyefinity多屏显示功能。同时混联测试中,A卡担当主卡时能借助ACE等特性能获得更好的性能也算是一个佐证。

MC点评:EMA混联值得期待
EMA一定大有可为,这是测试至此我们的第一感觉。相信测试结果已经可以回答本文一开始提出的所有疑问,解决大多数玩家面对DX12可以实现不同品牌、型号显卡混合并联时的诸多不解。很显然,A、N真的能在Windows 10下握手言和,而且这种系统原生的协作方式,在游戏优化到位的前提下,完全能够在协作效率上超越显卡厂商这么多年来一直坚持的SLI等原厂技术。重要的是,因为是集成在DX12中的重要特性,所以基于DX12 API开发的所有游戏在一开始就等于是在为多卡协同工作优化。比以往需要游戏厂商特意和显卡厂商合作,高度依赖原厂驱动的情况相比,适应性、实用性无疑更加出色。说到实用性,我们可以想象得到的是,当非链接型EMA和SFR成熟后,新的并联方式将带给笔记本电脑用户和升级用户更多实惠。当前几乎没有一台搭载独显的笔记本电脑没有额外的集成显卡,但游戏的时候都是闲置的。同时以往升级下来的显卡因为架构老旧,性能相对新产品差距较大,只能丢弃。而现在这两种让人无奈的情况都可能随着EMA的成熟而改变,任何一丝性能都有可能被系统利用起来,成为帮你跨过游戏流畅与否关键一帧的贡献者。
当然,此时此刻无法体验无链接EMA加SFR模式无疑让我们遗憾不已。在DX12游戏更加丰富,支持模式更多后,我们一定会第一时间为玩家们补上更全的测试。
用户评论

