



NVIDIA“Kepler”架构完测
“史上快、有效率的GPU!”&“以低的功耗代价换来为极致的性能!”——NVIDIA
凭借28nm先进工艺和全新的GCN架构,AMD的“南方群岛”家族在高端显卡市场上出尽风头。不过,随着研发代号为“Kepler”的NVIDIA下一代显示核心的发布,两大阵营的新一代强显卡终于棋逢对手。
显卡性能王位之争,现在才正式开始。
以彼之道的“小”胜 桌面“Kepler”首发测试
从GT200开始,NVIDIA的铁壳封装就再没让我们看过GPU的真身。
也是从那时开始,小核心策略成为了AMD反击NVIDIA的一个利器。
还是从那时候开始,NVIDIA的产品总能后发制人,长期占据显卡性能王座的位置。
这一切显得那么顺理成章,以至于我们从来没有想过NVIDIA会做出一个小巧的旗舰显示核心。事实上,你能想象出NVIDIA设计的小核心会是什么样子吗?
它是否还能保持性能上的领先优势?
在能耗比上是否能后来居上?
……
别想了,让GeForce GTX 680来告诉你一切!
NVIDIA的第一款“小”核心旗舰
3个月前,AMD发布了基于GCN架构的新一代旗舰显卡Radeon HD 7970。在我们的测试中,它以非常明显的优势战胜了当时NVIDIA的旗舰GeForce GTX 580。在接下来的时间里,玩家们都在等待NVIDIA发布新的产品,届时好对比选择自己的下一块玩物。按当时的推测,新产品要想稳获显卡王位,就必须拥有超过GTX 580至少40%的性能。想必又将是一颗核心面积在500mm2左右的规格怪兽。让大家没有想到的是,NVIDIA为我们准备的“Kepler”架构首款核心(GK104),竟是一颗核心面积不到300mm2的“小”核心。接下来,MC评测工程师会将GK104的特征划分为基础(计算)特性和功能特性分别进行介绍。其中功能特性将会以夹叙夹“测”的体验方式为你展现。
MC评测室在第一时间获得了NVIDIA送测的GTX 680样品,它的PCB长度约25.5cm,比公版GTX 580的27cm略短。散热器结构两者如出一辙,外观风格基本一致。只是外接供电接口方面GTX 680采用双6Pin,而非GTX 580的8Pin+6Pin。
,40nm工艺526mm2的GF100(GTX 480),40nm工艺520mm2的GF110(GTX 580)和28nm工艺294mm2的GK104(GTX 680)。可以看到除了GTX 680,其余都是核心面积高于500mm2的大家伙,良率和成本上看GK104肯定占优。而且也只有GK104没有采用金属壳封装,理论上成本优势会更明显。")
近两代NVIDIA旗舰显示核心。依次为65nm工艺576mm2的GT200(GTX 280),40nm工艺526mm2的GF100(GTX 480),40nm工艺520mm2的GF110(GTX 580)和28nm工艺294mm2的GK104(GTX 680)。可以看到除了GTX 680,其余都是核心面积高于500mm2的大家伙,良率和成本上看GK104肯定占优。而且也只有GK104没有采用金属壳封装,理论上成本优势会更明显。
公版GeForce GTX 680显卡



可能是为了节省PCB空间,GTX 680的外接供电接口采用了比较特别的错落式立体结构。

显示输出接口上GTX 680和GTX 580大不相同。NVIDIA第一次在公版显卡上加入了对标准Displayport接口的支持。不会是单单增加接口数量这么简单吧?支持Displayport的GTX 680有什么秘密?

GTX 680采用了4相核心加2相显存的供电设计,而GTX 580则为6相核心供电设计,能看出这颗小核心对供电的需求明显降低。
散热外,也能起到与金属背板类似的板卡加强筋作用。")
GTX 680的散热模块依旧内置了全覆盖的金属底座,这个设计除了能帮助GPU的周边器件(如显存)散热外,也能起到与金属背板类似的板卡加强筋作用。

公版散热器采用内置热管设计,外表上看不出热管,实际有3跟热管与底部吸热铜表面亲密接触。

来自海力士的0.3ns GDDR5颗粒,为GTX 680提供了高达6000MHz的等效显存速度。
{kind=link}
浓缩是精华 GTX 680架构基础特性解读
拜全新设计的显存控制器所赐,NVIDIA显卡在GTX 400/500时代主要靠扩展显存位宽来提升带宽的被动局面结束了。从表1中你能看到,GTX 680的等效显存频率默认就达到了6000MHz的高度。
、GF110芯片内核图。在芯片设计中,显存控制器、光栅和缓存等单元是相当占用晶体管资源和内核面积的部分。相比GF110,GK104在显存控制位宽,光栅单元数量和缓存大小上都有所减少。所以我们看到以往占据芯片中心大量面积的控制单元在GK104上的比例明显减小,计算单元/控制单元的比例明显增高。")
GK104(左)、GF110芯片内核图。在芯片设计中,显存控制器、光栅和缓存等单元是相当占用晶体管资源和内核面积的部分。相比GF110,GK104在显存控制位宽,光栅单元数量和缓存大小上都有所减少。所以我们看到以往占据芯片中心大量面积的控制单元在GK104上的比例明显减小,计算单元/控制单元的比例明显增高。
此外,你能发现GTX 680相对GTX 580在晶体管数量上的提升是非常有限的。GTX 680内含35.4亿个晶体管,相比GTX 580增幅仅18%,这在工艺升级的跨代产品对比中是很少见的。相对的,同样是40nm到28nm的升级,HD 7970就从HD 6970的26.4亿晶体管大幅提升到了43.1亿,增幅达到63%。GTX 680如此小的核心如何保证性能提升?关键问题在效率上。
,每个GPC内含2个SMX计算集群,共计8个SMX计算集群。")
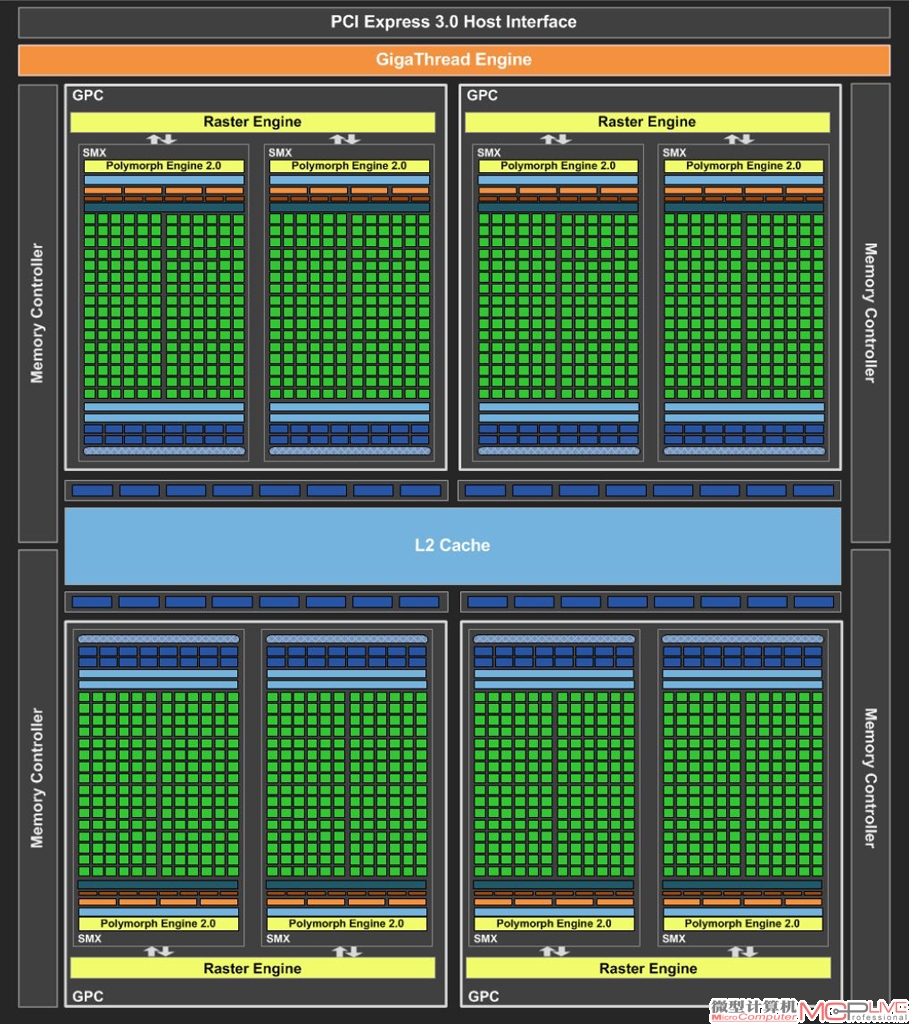
GK104整体架构图。它一共包含了四个图形处理簇(GPC),每个GPC内含2个SMX计算集群,共计8个SMX计算集群。
{kind=link}
{kind=link}

GK104 GPC架构图。每一个GPC都是一个比较完善的GPU次级单位,包含了图形渲染所需的几乎所有组件。每个GPC拥有一个共享的光栅引擎和两个相对独立的SMX计算集群。
,32个64bit存取单元(LD/ST),32个特殊函数单元(SFU),16个纹理单元(Tex)和缓存等组件。")
GK104 SMX单元架构图。它包含了Polymor ph Eng i ne 2.0引擎,192个CUDA计算单元,4个指令调度器(Warp Scheduler,包含两个指令发射器Dispatch Unit),32个64bit存取单元(LD/ST),32个特殊函数单元(SFU),16个纹理单元(Tex)和缓存等组件。
高度优化的计算/控制单元比例
从GK104整体架构图中我们能看到颇为熟悉的GPU——GPC——SMX——CUDA组成结构。很明显,基于“Kepler”架构的GK104传承了不少“Fermi”架构的设计思路,至少组织结构上没有太大变化,宏观上都采用了4个GP C的并行设计。不过仔细观察后会发现,虽然GK104和GF110在GPC单元数量上一致,但GK104的每个GPC模块仅包含2个SMX集群,而GF110的每个GPC模块则包含了4个SM集群。因此,GK104在SMX这一层上的规格相对前辈减半。要知道SMX这一层级的单元承载着诸如几何输出单元等重要计算模块的Polymorph Engine引擎,跟曲面细分等计算能力直接挂钩。简单点说SMX数量的减半也就意味着曲面细分计算单元的数量少了一半。那是不是在“Fermi”上强势的曲面细分应用优势将丢失呢?其实不然,NVIDIA在减少Polymorph Engine数量的同时,增强了每个Polymorph Engine引擎的效率。在一个时钟周期内,实现了比原有单元翻倍的吞吐性能。NVIDIA称它为Polymorph Engine 2.0引擎。因此,拥有8个Polymorph Engine 2.0引擎的GK104和拥有16个Polymorph Engine引擎的GF110,理论上每时钟周期几何处理能力是大致相当的。但使用了28nm新工艺的GTX 680在频率上更有优势,所以整体几何处理效能,特别是高负载状态下的性能GTX 680会比GTX 580更强劲。
除了更新Polymorph Engine引擎,以提高GK104芯片上单位面积的计算性能。NVIDIA的工程师还优化了GK104上的基础计算架构,以期达到在尽可能小的芯片内塞进更多计算核心的目的。如果你稍微留意过GF110的SM构成,你会发现“Fermi”的每个SM的内只有32个CUDA核心,也就是说SM内的一套逻辑控制单元只管理32个核心的工作调度。而GK104上,这个比例被放大到了192个。降低逻辑控制单元和指令发射器的比例,用较少的逻辑单元去控制更多的CUDA核心。从这个层面上来看,NVIDIA似乎借鉴了AMD经典的SIMD架构设计思路。有趣的是我们之前分析GCN设计构思时,发现AMD才大刀阔斧的改进了SIMD,向“Fermi”的MIMD架构靠拢。不管怎么说,拜这种思路所赐,GK104的流处理器数量(CUDA数量)达到惊人的1536个,在晶体管数量增加不到18%的情况下,将流处理器数量增加到了GF110的3倍。

硬件指令调度与软件调度的对比。你能看到整体的调度架构没有明显变化,但硬件执行过程被简化,硬件单元减少。
此时相信有读者会担心“降低控制单元的比例那是不是意味着NVIDIA从G80开始赖以成名的高效率将一去不复返?”理论上,肯定会导致效率下降,但真实情况是效率下降的问题并不严重。而这多亏了指令调度的“软”着陆。事实上,NVIDIA工程师发现线程的调度有一定的规律性,编译器所发出的条件指令可以被预测。在“Fermi”及以前,这部分工作是由GPU内专门的硬件单元来完成的。而在GK104上,这部分工作将根据预测性,交由简单的软件程序来处理。这样就能节约不少晶体管,简化CUDA单元,简化控制和调度单元的硬件设计。不过我们担心由此开始,N家的显卡也将出现比较明显的软件优化依赖,驱动或游戏的优化不到位将会明显影响“Kepler”架构的发挥。

每时钟周期“Fermi”、“Kepler”加法操作对比。你可以看到在同样的吞吐率下,“Kepler”的逻辑单元是“Fermi”的1.8倍,但是逻辑单元的耗电还低10%。时钟电路的面积一样,“Kepler”的耗电量只有“Fermi”的一半。
为了能耗比,频率不再分家
细心的读者可能已经从表1中看出GTX 680的规格中不再单独列出Shader频率,这是怎么回事?按照NVIDIA的说法,从G80时代开始采用的异步Shader频率设计是为了能在尽量少的芯片面积下实现更高的吞吐量。但这是以牺牲功耗为代价的,这种设计需要2倍于同步频率的流水线硬件,和双倍的重定时功耗。每个硬件单元的耗电高会达到4倍于同步频率的水平。现在,“Kepler”的设计改变了以往架构流处理数量明显不足的劣势,没有必要再沿用这种高功耗的设计。毕竟“Kepler”的目标不仅是提高性能还更注重能耗比。
解除绑定,让纹理质量向极致靠拢
在图形计算过程中,物体表面颜色细节需要纹理单元(Textuie)和Shader配合作业。在“Kepler”之前,GPU内每个Shader在一个周期内能访问的纹理单元数量是非常有限的。根据DirectX 11图形API的要求和映射表大小的限制,这个数量被限制在1∶128。而“Kepler”架构则消除了渲染场景时Shader可用独立纹理数量的限制。它允许着色器直接从内存中引用纹理,不再需要传统的映射表。依照NVIDIA的说法,着色器与纹理数的比例达到1∶100万也未尝不可。届时我们就能在游戏中看到更多如照片或电影般的精细贴图场景。只是目前这个特性只能在OpenGL中提供,未来将可能通过NVAPI在DirectX中实现,或者等待新版本的DirectX加入对该特性的支持。

解除绑定的免装箱机制不仅能让纹理更加精细,还能进一步降低CPU占用率。上图是以不同方式载入三张纹理到显卡的过程,左图为传统的装箱表式贴图配置,需要CPU执行三次配置装箱表动作,而右面“Kepler”体系的免装箱表贴图则完全消除了这三个动作。
好了,有关“Kepler”技术的介绍到此告一段落。有关GTX 680更多的功能特性就留在实际体验环节来为大家解读,先让我们一起来看看在架构上大幅改进后的GTX 680能我们带来怎样的实际游戏性能。
GTX 680性能评测&功能特性解读
为了尽量避免系统瓶颈对显卡性能的影响,我们在当前强的桌面级平台上对GTX 680进行了性能测试(测试平台详情请见下表)和功能特性体验。性能上,主要考察了各款显卡在3DMark基准测试和实际游戏测试中的表现。其中,游戏体验以包括《战地3》、《尘埃3》在内的6款DirectX 11游戏为主, 辅以DirectX 10(《FarCry2》)和DiretX 9(《使命召唤:现代战争3》)游戏各一款来综合考量显卡。

GTX 680 GPU-Z截图。GPU-Z0.6.0版本已经能很好地识别GTX 680,各项参数都能正常准确的显示。其中原Shader频率的窗口改为显卡的Boost频率。
GTX 680性能实测
问鼎1080p毫无压力
1920×1080是当前大多数玩家使用的分辨率。在这个分辨率下,GTX 680能轻松压制住上代旗舰——GTX 580。基准测试中,它的领先幅度超过了我们之前预期的40%的心理底线。但是实际游戏中这个幅度又有所打折。特别是在面对开启抗锯齿的压力环境下,GTX 680相比GTX 580的领先优势会大幅下滑。这显然是受到了显存位宽和光栅单元减少的负面影响。总的来说,这次换代的性能提升幅度,勉强满足了用户的期望。
相比HD 7970,GTX 680领先还是毋庸置疑的。从表2中你能看到,GTX 680的游戏性能平均领先HD 7970约12%,看似和基准测试极为吻合。不过仔细查看数据你会发现,在《异形大战铁血战士》、《地铁2033》以及《使命召唤:现代战争3》中,两卡的性能其实大致处于一个水平线上。而在另外几款游戏中,GTX 680的领先优势又明显超过了平均值。看来我们对“Kepler”软件依赖性的担心并非多余。相比“Fermi”(GTX 580),“Kepler”(GTX 680)在不同游戏中的表现更加不稳定。不过,换个角度看,这也许是“Kepler”的一个优势。毕竟它能通过软件(如驱动)的后续优化,获得更大的性能提升。
面对自家的上代双芯旗舰GTX 590时,GTX 680的情况和HD 7970面对HD 6990时一样。在部分游戏中GTX 680有匹敌、甚至超越GTX 590的表现。但大部分游戏中,GTX 680还是明显落后,单拳实难敌双手。
2560分辨率谁是真卡皇?
坦白说,对于GTX 680和HD 7970这样的顶级显卡,1080p分辨率已经不足以构成渲染压力。超过100的低帧数让测试变成了纯数字的比拼,此时我们已经感觉不到游戏体验的变化。所以,MC评测工程师决定将游戏分辨率提升到2560×1440的高度。在这个分辨了下开启全特效运行大型3D游戏,几乎能榨干显卡的计算性能。谁能顶住这个压力成为新一代卡皇,获得顶级玩家的青睐?
在这个分辨率下,所有参测显卡的测试成绩都较1080p时大幅下滑。GTX 680基准测试的GPU成绩下滑59.5%,下滑幅度比HD 7970的56.5%更严重。游戏实测的情况和基准测试比较吻合。GTX 680和HD 7970的平均帧率都大幅下滑,GTX 680相比HD 7970的领先优势较1080p分辨率有所降低,但整体依然胜出约7个百分点。很显然,GTX 680再胜一局,新一代的卡皇非它莫属。但不得不说的是,在这种高分辨率下,即使是GTX 680也会在部分游戏中失去可玩度,平均帧数达不到30帧。从这个角度看,不论是A家还是N家,顶级单卡都不足以满足高端玩家的需求。顶级多卡并联才是高端用户的新追求。那GTX 680 SLI系统的并联效率如何呢?让我们这就来一窥究竟。
双卡并联,高分辨率的佳舞台
所幸第一时间到达MC评测室的除了NVIDIA送测的公版GTX680产品,还有iGame九段680。这让我们能第一时间体验新架构的双卡互联,看看“Kepler”的互联效率是否出色,以及GTX 680双卡SLI的游戏兼容性是否良好。

iGame九段680外观看起非常朴实,其实那是因为没上色!
九段680的做工和设计是个亮点,但这并不是我们本次测试关心的重点。本文侧重的是GeForce GTX 680的芯片测试,下期我们会挑选一些有代表性的GTX 680显卡进行测试。(欢迎大家登陆MCPLIVE.CN 选出你心目中出色的GeForce GTX 680显卡,我们将根据你的选择着重进行对应产品测试。)SLI的组建方式并没有因架构而改变。将两卡分别插在主板的PCI-E x16接口上连上SLI桥接器,在N VIDIA驱动控制中心将系统性能设置为优化,系统就会自动将双卡设置为SLI并联渲染模式。我们分别在1920×1080和2560×1440两个分辨率下考察了GTX 680双卡SLI系统的性能。在3DMark基准测试中,SLI系统的效率表现一如既往的出色。不论是1920×1080还是2560×1440的高分辨率,SLI系统的图形计算性能得分相比GTX 680单卡都几乎翻倍。不过根据我们以往的测试经验,显卡厂商的驱动针对基准测试软件的优化都相对较好,而这并不能代表实际游戏的效率。所以接下来的游戏测试才是重点。

九段680的散热器采用3风扇设计,搭配了5根热管和较厚的鳍片。这组合相比公版产品魁梧了不少,也让这卡的安装位需占用3个卡槽。
游戏测试的情况相对复杂了不少。在基于DirectX 9的《使命召唤:现代战争3》测试中,SLI的效率并不理想,相对单卡的领先优势不到20%。1080p画质下开启4×MSAA后甚至有倒退情况。但SLI在DirectX 10/11游戏中的表现较为出色,相对单卡系统平均帧率提升非常明显。虽然整体不及基准测试的领先幅度大,但在将测试分辨率拔高到2560×1440高度的时候,SLI系统的效率就能很接近基准测试体现的情况,游戏平均帧率相对单卡系统几乎翻番。

背面的扩展供电接口和扩展供电模块依旧是九段的独家秘方,配合上双8pin外接供电接口,看来九段是想玩家们好好OC一番。
此外,MC评测工程师注意到,新架构下的SLI系统并未能完全解决并联计算的低帧率倒退问题。在我们的测试中依然偶有SLI系统低帧率不及单卡系统的情况发生。所以我们建议,只是希望在1080p分辨率下畅玩游戏的玩家,性能强劲的GTX 680单卡就已经能够满足你的需要。但已经沉迷或即将被高分辨率呈现的精美画质所征服的玩家,请义无反顾的组建SLI吧。能在2560×1440这种分辨率下畅玩《战地3》这样的画质党游戏,确实是一种享受。
通用计算&曲面细分,架构改变带来明显影响
在GTX 400/500时代,NVIDIA显卡在通用计算和曲面细分方面的出色表现大家有目共睹。这不仅帮NVIDIA赚足了玩家口碑,也让NVIDIA的产品在企业级市场风生水起。此次GTX 680经历了架构上的明显改变,原本纯正的MIMD设计思路被借鉴了SIMD结构的MIMD思路取代。在这个前提下,新架构产品能为我们带来怎眼的并行计算性能,大家都非常关注。
我们测试了GTX 680/580和HD 7970在通用计算软件GPC Benchmark OCL和Compute Mark中的表现。GTX 680的成绩并不理想。
GPC Benchmark OCL中GTX 680小胜GTX 580,明显落后HD 7970。ComputeMark中GTX 680证明了自己的实力,领先GTX 580 69%,但依旧小幅落后于HD 7970。“Kepler”架构需要依靠软件优化来弥补并行计算效率的缺点,在这两款“老”软件中体现得比较明显了。
至于曲面细分的能力,我们体验了各款显卡在Unigine Heaven 2.5中的表现,曲面细分设置统一开启到Extreme级。你能看到在负载较轻的1080p分辨率中,未开启抗锯齿效果的状态下,GTX 680相对GTX 580和HD 7970的领先优势都非常明显。随着分辨率和抗锯齿要求的提升,这种领先幅度逐步下降。直到苛刻的测试条件,GTX 680还是能力压GTX 580。可见Polymorph Engine 2.0引擎的性能提升幅度应该达到了NVIDIA宣称的2倍。不过此时GTX 680相对HD 7970的优势就微乎其微了。毕竟GTX 680的Polymorph Engine引擎已从GTX 580的16个大幅下降到8个。纵使效率再高,也难以完全消除规模上的劣势。能借如此小规模胜过HD 7970已经难能可贵。而且Unigine Heaven 2.5考验的也不仅仅是曲面细分性能,相对来说它的测试结果是比较综合地反映了显卡的性能水平。
人无我有,人有我精GTX 680功能特性体验
Boost与超频并不冲突
“GPU Boost”,相信玩家能第一时间从名字上大致猜出这个功能的作用。是的,它能在不超过热功耗限制的条件下根据核心的负载情况,动态提升显卡的核心频率。例如GTX 680核心频率为1006MHz,而它的Boost频率则为1059MHz。那是不是高只能加速到1059MHz呢?这个功能对显卡超频是否有影响?以下三图则是我们体验结果的简单展示。
单卡3屏3D Vision Surround,想说爱你不容易!
单卡就能组建3屏3D Vision Surround是GTX 680的一大特色。在GTX 580时代,我们只能通过SLI来实现这个功能。之前我们在介绍产品时曾提到,GTX 680是NVIDIA第一款在公版显卡上提供标准Displayport接口的产品。其实这个Displayport接口就是为3+1屏3D Vision Surround而生。和AMD的产品一样,GTX 680单卡3屏Surround必须使用到Displayport接口(加两个DVI接口)。

EVGA的PrecisionX软件。它是目前好用的GPU Boost功能软件。在这里强调一点GPUBoost并不是单纯的超频。GPU Boost的原理是利用热设计功耗限制,动态调节频率来解决GPU内部运算单元复用率不足的矛盾。
。")
默认状态下,我们开启《使命召唤:现代战争3》时,能从软件中看到GPU被动态加速到了1058MHz。而开启《战地3》时,GPU则被动态加速到了1123MHz(如上图)。

GPU Boost并不影响超频。在将功率限制拔高20%之后,我们就能轻松地将核心频率超到1156MHz。而此时,GPU Boost的作用依旧在。它能在120%于原散热设计功耗的范围内,将GPU频率动态拔高到1275MHz。
不一样的是,GTX 680能用剩下的H DMI接口输出第四个屏幕,只是这个屏幕不具备3D Vision能力。原本这个功能足够炫酷,但是带有Displayport接口的3D Vision显示器实在罕见。我们也未能在第一时间体验这个功能,只能在“2D”模式下尝试了3屏Surround。面对5760×1080的分辨率,单卡GTX 680的表现勉强及格。包括《Crysis2》在内的众多高要求游戏能比较顺畅的运行,只是平均帧数并不好看,只有30左右。

3+1屏3D Vision Surround能带给你震撼的影院级游戏效果。
TXAA画面党福音
按照NVIDIA的说法TXAA是全新一代硬件渲染的抗锯齿技术,可以提供电影级别的画面品质,专为发挥GTX680强大的纹理性能而设计。目前TXAA分为TXAA1、TXAA2两个级别,TXAA1可以实现8xMSAA的效果,执行效率与2xMSAA相当,而TXAA2则会提供更高的画面品质,但资源消耗也仅4xMSAA的水平。

TXAA1与4xMSAA条件下的画面对比,TXAA1硬件消耗只有后者的一半,但是性能却能到达远超后者的8xMSAA的水平。
NVENC专用硬件 视频编码再加速
其实在“Kepler”之前,NVIDIA的显卡就能利用CUDA核心对视频编码进行加速。当时已经能提供比处理器快数倍的性能,不过后来被Intel在处理器上集成的专用视频编码引擎反超。事实上,CUDA核心并非视频编码的专用硬件,所以能耗比上的表现没有专用引擎出色。现在NVIDIA在“Kepler”上加入了专有的硬件编码单元——NVENC。它支持对H.264等高清视频的硬件实时编码,同功耗下的效率较CUDA编码又提高了4倍。

当前NVENC仍然需要专门的API和SDK,只有少量的如CyberLink_MediaEspresso等软件能支持。要到今年晚些时候,CUDA开发者才可以使用高性能NVENC转码器。届时将可以通过CUDA通用计算进行视频预处理,再使用NVENC进行编码。这能使工作效率进一步提高,并且相互不影响。
功耗温度简测:未食言!
在GTX 680发布前,NVIDIA CEO黄仁勋先生就说过,即将发布的“Kepler”架构是个高度重视能耗比的产品。根据惯性思维,我们很难相信“Kepler”能在性能领先对手的前提下,将能耗控制得更低。直到得知GTX 680核心只有294mm2后,我们才对这句话有了几分信心。实际情况如何,GTX 680到底多省电?我们用Furmark对它进行了拷机测试。待机状态,GTX 680平台的功耗比HD 7970低9W,优势并不明显。而满载状态,GTX 680则比HD 7970低了35W。为了避免功耗控制对Furmark成绩的影响,我们还对显卡在运行《战地3》时的功耗进行了对比。此时,除了GTX 580(功率限制保护),GTX 680和HD 7970的功耗都比Furmark拷机时要低,HD 7970比GTX 680高出20W。好了,游戏加拷机足以说明问题了。GTX 680的功耗控制能力确实如黄仁勋所言,非常出色。其能耗比表现明显超过了HD 7970,改变了以往一直是AMD产品在能耗比方面占优的局势。而温度方面,不论是AMD还是NVIDIA,公版产品的控制能力都不出色,建议玩家们入手后自行更换更优秀的散热系统。
3D游戏?超极本也没问题!
除了GeForce GTX 680之外,针对笔记本电脑的“Kepler”移动版本GeForce GT 640M也已经同时发布,我们自然也要对其进行测试。有些让人意外,强调轻薄便携和长效续航的超极本,竟然是首个采用“Kepler”架构移动显卡的产品。这实际上从更直接的角度说明,系统厂商对移动版本的“Kepler”在功耗控制方面的能力非常有信心,否则谁会想到在从来没有接触过独立显卡的超轻薄机型上,居然真的就有了玩3D游戏的希望。
采用GeForce GT 640M移动显卡的超极本是一款15英寸机型,机身厚度和重量分别是20mm和2kg左右。现在的超极本标准确实放得很宽了……为了更准确地为GeForce GT 640M的性能表现定位,我们选择了分别采用GeForce GT 630M和GeForce GT 540M的两款笔记本电脑作为参照。相信各位已经从参测样机规格表看到了,作为对比的两款样机的处理器都是标准电压版本,比起GeForce GT 640M样机的超低电压版本处理器,在性能方面要强很多。
是的,这不公平。不过在超极本上采用独立显卡的情况没有先例,没有其他采用超低电压版处理器和独立显卡的机型可供对比。而且如果在这样的配置下,GeForce GT 640M还能占到优势的话,那就更能证明“Kepler”的强大了。顺便说一句,虽然同为GeForce 600M系列,但是GeForce GT 630 M的核心架构依然是上一代的“Fermi”,基本上可以把它看成上一代GeForce 500M系列的马甲版。
虽然对“Kepler”的强劲性能已经有所了解,但是GeForce GT 640M的测试表现仍然让我们很吃惊。在处理器性能偏弱的条件下,GeForce GT 640M的3DMark测试和游戏测试成绩依然领先于GeForce GT 540M和GeForce GT 630M,而且领先幅度基本都在50%左右。也就是说,GeForce GT 640M的性能已经是另外一个档次的概念,而这样的提升幅度在以往的显卡更新换代中是很少出现的。这让我们对今年笔记本电脑的游戏性能很期待,在搭配性能更高的标准电压版本处理器之后,基于“Kepler”架构的移动版本显卡应该足以应付绝大多数大型3D游戏的性能需要。事实上,NVIDIA也表示今年会有8家品牌厂商推出专属游戏定位的笔记本电脑(去年只有5家),希望笔记本电脑也拥有出色游戏性能的玩家有福了。
值得一提的是,在考察通用运算性能的ComputeMark 2.1,以及针对曲面细分性能的天堂2.5测试中,GeForce GT 640M也体现出了高人一等的实力,曲面细分性能甚至超出了另外两款显卡接近1倍。
有些遗憾的是,采用GeForce GT 640M的测试样机出了一点状况,没办法测试电池续航时间。因此关于移动版“Kepler”显卡的功耗测试,特别是它对电池续航能力是否有影响以及有多大影响的问题,我们只能在今后的测试中去寻找答案。不过从超极本都能采用GeForce GT 640M显卡的情况来看,移动版“Kepler”显卡的功耗和发热量控制应该是比较到位的,否则谁也不愿意在自己的产品中放一个“烫手山芋”。

